(通訊員黃慧、成皓飛 供圖郝陽歧、阮雪琴)9月24日,由武漢大學信息資源研究中心,美國北德克薩斯大學信息科學系、圣何塞州立大學信息學院、南卡羅萊納大學信息與通信學院,孟加拉國達卡大學信息科學與圖書館管理系等聯(lián)合主辦的國際信息科學與技術學會ASIS&T SIG-KM International Research Symposium 2022在線上召開。來自中國、美國、波蘭、哥倫比亞、愛沙尼亞、孟加拉國、印度、菲律賓、巴基斯坦、伊朗、尼日利亞等國家和地區(qū)的百余位專家學者圍繞主題“信息彈性社會中的知識管理”(Knowledge Management in an Information-Resilient Society)進行了深入交流。本次研討會由主旨報告、論文宣講、學位論文交流、海報展示等部分組成。

國際信息科學與技術學會(ASIS&T)主席Naresh Agarwal教授致開幕辭。他對來自世界各地參會的專家學者表示歡迎,希望此次會議是一個有活力且有重要意義的會議,期待大家能夠進行深入交流與討論,在精彩的思想碰撞中得到啟發(fā),并通過會議建立美好的友誼。ASIS&T SIG-KM主席、武漢大學信息管理學院教授、武漢大學信息資源研究中心數據管理與知識服務研究室主任安璐致辭,感謝ASIS&T主席、主旨報告人、論文作者與研究人員的積極參與,指出每個人都是兼職的知識管理者,期待與會人員能夠暢快交流,收獲良多。ASIS&T SIG-KM候任主席(Chair-Elect)、北德克薩斯大學信息學院董事教授(Regents Professor)Jeff M. Allen向各位參會者表示歡迎,并介紹了SIG-KM組成人員。
武漢大學信息管理學院院長、信息資源研究中心研究員陸偉教授作題為“Academic Keyword Semantic Function Identification and Its Application”的主旨報告。他針對當前詞匯功能識別研究依賴于人工構建的特征,并缺乏公開可用的數據集的局限性,結合基于多種不同策略的關鍵詞功能識別模型的優(yōu)缺點,提出同時在低資源和高資源情境中都具有良好表現的詞匯功能識別模型MPT。該模型能應用于作者關鍵詞選擇行為、學術論文新穎性度量、機理抽取等研究。
陸偉指出,詞匯功能即為詞匯在特定語境中承載的語義功能。在不同的學術領域,詞匯功能也有所不同。如計算機科學領域的詞匯功能主要有數據、工具、度量標準,醫(yī)學領域的詞匯功能主要有藥品、疾病、基因。關鍵詞是一種能夠對文本內容和主題高度凝練概括的功能性詞匯,標識學術文獻中的關鍵詞功能能夠為下游任務提供底層索引支持。因此,他認為,進行詞匯功能識別的研究具有重要的理論意義與實踐價值。
卡塔爾計算研究所社會計算小組(QCRI)首席科學家、Information Processing & Management主編Jim Jansen教授作題為“The Illusion of Data Validity: Why Numbers About People Are Likely Wrong”的主旨報告。

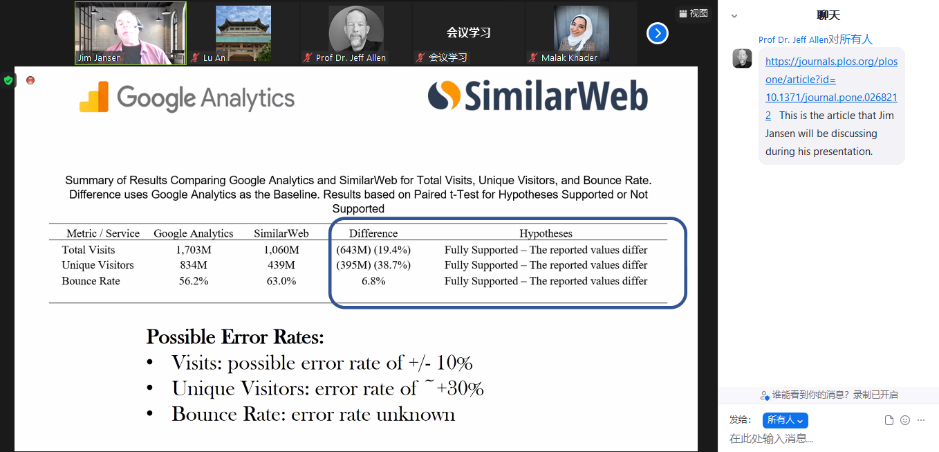
Jansen從開爾文勛爵關于數字的表述談起,以其研究報告“Measuring user interactions with websites: A comparison of two industry standard analytics approaches using data of 86 websites”中的數據分析為例,對數據有效性的幻覺進行了闡述,指出一些與人相關的數字可能是錯誤的。該報告通過測量86個網站的用戶與網站的互動數據,對基于兩種不同行業(yè)標準的分析方法進行了比較。通過研究發(fā)現,兩種分析方法得出的指標結果均有顯著不同。Jansen認為,基于兩種分析方法得到的指標可能都既不準確,又不精確(即錯誤),因為這些指標在測量過程中都存在許多誤差。他指出,當我們對與人有關的數字進行分析時,往往認為我們在計算數字,然而實際上,我們通常是在測量,測量就會存在一定的誤差。他提出,在處理有關人的數字時,應檢查是在計算還是測量,如果是在測量,則應當認識到誤差的來源。
美國洛杉磯大學、哥倫比亞波哥大羅薩里奧大學管理與商業(yè)學院、印度沃森大學、巴基斯坦旁遮普大學信息管理學院、尼日利亞卡拉巴爾大學、南京大學信息管理學院、北京大學健康醫(yī)療大數據國家研究院、復旦大學發(fā)展研究院、中國農業(yè)科學院農業(yè)信息研究所、中國醫(yī)學科學院醫(yī)學信息研究所、上海外國語大學、河北大學管理學院等高校和科研院所的師生分享了他們在中小企業(yè)聯(lián)盟管理能力與績效、政府科學-研究-技術政策研究、學術圖書館員的五大人格特質與知識共享意愿、用戶需求的網絡電影元數據集開發(fā)、數據庫豐富技術實現數據與文獻的聯(lián)系、多標簽用戶畫像和知識表征的知識服務系統(tǒng)多元化推薦模型、知識庫與文本的鏈接、用于理解Covid-19臨床知識概念間關系的第三因素變量發(fā)現等主題上的研究成果,并與參會人員進行了熱烈討論。

上海大學、武漢大學、吉林大學、巴基斯坦巴哈瓦爾普爾伊斯蘭大學等高校的研究生分享了知識網紅如何吸引用戶為知識付費、危機事件跨平臺網絡信息的最佳閱讀路徑、新冠疫情背景下群體極化的影響因素及形成機制、巴基斯坦大學圖書館電子論文數字化庫建設展望等主題的學位論文。
美國北德克薩斯大學、愛沙尼亞塔林理工大學、菲律賓中央大學、中山大學等高校的學者展示了他們在群體智慧模型、基于Web的圖書館聊天機器人的實現與應用、醫(yī)療保健組織知識風險管理框架、高校知識產權信息服務等方面的研究內容。
Jeff M. Allen也分享了他在群體智慧模型上五年多來的研究成果。他認為,智慧由多種不同特征和美德經過復雜的交互作用演化而來,這些特征和美德可以聚集在知識和經驗、自我理解、理解他人三者之中。當一個人或一群人利用他們的知識經驗和理解來識別模式、聯(lián)系和基本原則,從而做出正確的判斷和明智的決定時,智慧就可以從知識中“進化”而來。集體智慧是由一個相互關聯(lián)的群體培養(yǎng)和發(fā)展起來的智慧行為的綜合集合,其目的是為群體、社區(qū)和社會確定一個有益的行動方案。
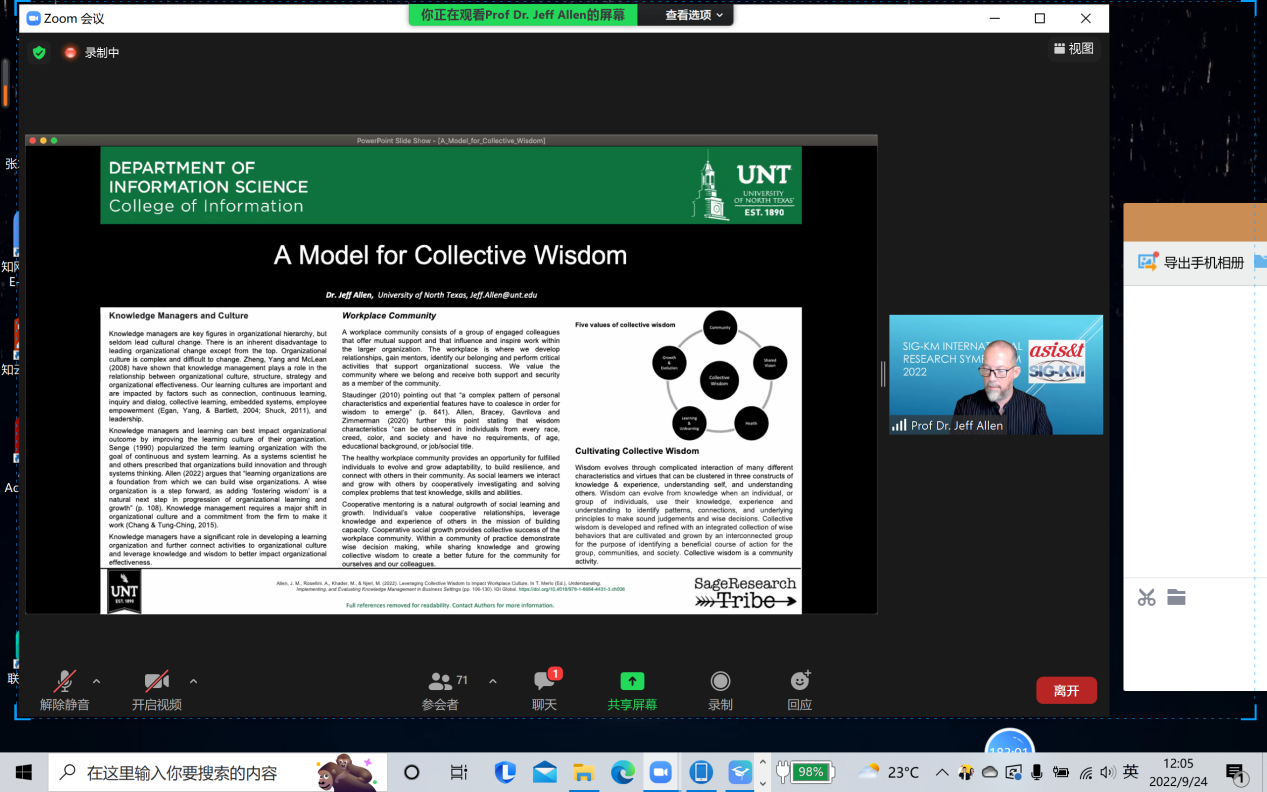
Jeff M. Allen提出了群體智慧模型,該模型描繪群體智慧發(fā)展和形成所需的五個要素:社區(qū)(Community)、共同愿景(Shared Vision)、健康(Health)、學習與遺忘(Learning & Unlearning)、成長與演化(Growth & Evolution)。首先,關于社區(qū),我們在家庭、工作場所等社區(qū)所分享的一切知識,其實都是在培養(yǎng)一種群體智慧。其次,社區(qū)成員能夠有意愿、自由地分享知識的前提在于他們都有共同的愿景。共同愿景能指導社區(qū)成員決定當下要做什么以及要達成什么樣的目標。其三,社區(qū)需要有健康良好的發(fā)展環(huán)境。只有在健康的組織或工作場所進行合作與交流,人們才有可能進行認識、分享和學習。同時,我們要不斷學習,不僅是學習自身領域的知識、技能,我們還需要去探索那些我們從未到達的領域,挖掘新的事物、新的學問。最后是成長與演化,我們所積累的一切知識學問都不是靜止的,而是不斷發(fā)展、不斷進化的,并且只有經過這樣的歷程,這些知識與經驗才能真正內化成我們所用的智慧。
針對會議分享的論文、學位論文、海報,研討會分別評選出了3名獲獎者和1項榮譽提名獎。(責編雷婷)
